A Rust thread pool
I’ve written a few toy games in Rust in the past few years1. Most recently, I opted to use async Rust via futures and WGPU. The outcome was surprisingly effective. I was seeing frame rates in the range of 200-1000 frames-per-second in a 3D game with a rudimentary discrete AABB-based physics and entirely generated terrain. It handled both compute-intensive as well as IO-bound tasks on my behalf. I needed to go from async back to sync for the game’s render loop. My solution was to block on a channel communicating with some actor process. However, I ran into issues trying to set up a WASM build, since this would block the only thread. I had more issues, but it’s been a while since I’ve worked on this toy project.
I realized that the abstractions were starting to creak, and I’m sure I could eventually get this work. For example, a game engine called Bevy has done so – and very elegantly, I might add.
So, in my perpetual journey to reinvent the wheel for my own education, I wanted to implement something that could take some tasks that are specified as simple callbacks (no async), do some background compute work and return the result. This is commonly known as a thread pool.
As alluded to above, this is not ideal for (slow) IO, as you would just end up blocking a thread while, potentially, nothing is happening. My solution to this is to put on my blinders and carry on implementing a basic thread pool.
Implementing a thread pool
Let’s start our project:
cargo new wadingpool
A wading pool is a shallow pool for children to play in. Another colloquial term that’s more familiar to me is a “kiddie pool”. A metaphor for how this is not a recommended implementation for actual use.
My goal to aid in my understanding is to have a full implementation only using safe Rust and the Rust standard library2. So, to start with the abstraction and move backwards, I want something that looks like the following:
let mut pool = ThreadPool::new(8);
let (tx, rx) = std::sync::mpsc::channel();
pool.spawn(move || {
// do some computation
let _ = tx.send(x);
});
Note that we can just leverage a multi-producer single-consumer channel to communicate between the tasks and our main thread. There’s no need for the use of clever generics and task handles with this implementation, and it still stays within the rules of using the standard library.
Let’s prepare our ThreadPool type:
use std::thread::JoinHandle;
pub struct ThreadPool {
threads: Vec<JoinHandle<()>>,
}
We want to be able to create a new ThreadPool with some number of backing
threads, so next is the implementation of the new function:
use std::num::NonZeroUsize;
impl ThreadPool {
pub fn new(size: NonZeroUsize) -> Self {
let size = size.get();
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
let thread = std::thread::spawn(move || {
// park the thread for now.
std::thread::park();
});
threads.push(thread);
}
Self { threads }
}
}
I opted to use a NonZeroUsize to enforce the type constraint that thread count
must be at least 1, but it’s up to the consumer to choose whether to panic or
return an error3. Next, we need to be able to send tasks to our threads. The
easiest way to achieve this is through an mpsc::channel, however, we want
multiple consumers. We can achieve this by wrapping it all up in a Mutex.
With this in mind, we can update our ThreadPool implementation. I’ve created a
type alias for the callback called Task since it’s quite a long type
signature.
use std::sync::{self, mpsc::Sender, Arc, Mutex};
type Task = Box<dyn FnOnce() -> () + Send>;
pub struct ThreadPool {
threads: Vec<JoinHandle<()>>,
sender: Sender<Task>, // new
}
impl ThreadPool {
pub fn new(size: NonZeroUsize) -> Self {
let size = size.get();
let mut threads = Vec::with_capacity(size);
let (sender, receiver) = sync::mpsc::channel::<Task>();
let receiver = Arc::new(Mutex::new(receiver));
for _ in 0..size {
let receiver = receiver.clone();
let thread = std::thread::spawn(move || loop {
if let Ok(task) = {
let rx = receiver.lock().unwrap();
rx.recv()
} {
task();
}
});
threads.push(thread);
}
Self { threads, sender }
}
pub fn spawn<F>(&mut self, callback: F)
where
F: FnOnce() -> () + Send + 'static,
{
self.sender.send(Box::new(callback)).unwrap();
}
}
Surprisingly, in just a handful of lines of code, we have a passable implementation of a thread pool. However, we may want to be able to gracefully terminate the thread pool before our program exits. The operating system will reclaim the resources, but we may have an application-specific reason to first do clean up.
First, we need to update the struct definition of the ThreadPool.
pub struct ThreadPool {
threads: Vec<JoinHandle<()>>,
sender: Option<Sender<Task>>, // updated
}
Then two places need some simple adjustments:
impl ThreadPool {
pub fn new(size: NonZeroUsize) -> Self {
...
Self {
threads,
sender: Some(sender),
}
}
pub fn spawn<F>(&mut self, callback: F)
where
F: FnOnce() -> () + Send + 'static,
{
let Some(sender) = &mut self.sender else {
// A critical bug, there is no recovery from here.
panic!("ThreadPool sender must exist before drop");
};
sender.send(Box::new(callback)).unwrap();
}
}
Then, we need to handle the error on the receiving end of a channel which occurs when the sender is dropped.
// in ThreadPool#new
let thread = std::thread::spawn(move || loop {
let res = {
let rx = receiver.lock().unwrap();
rx.recv()
};
match res {
Ok(task) => {
task();
}
Err(_) => {
return;
}
}
});
Lastly, we need to drop the sender and wait for the Threads to complete (by
matching on the error). The most natural place to do this is inside of the
Drop implementation of the ThreadPool:
impl Drop for ThreadPool {
fn drop(&mut self) {
let mut sender = self.sender.take();
drop(sender);
while let Some(thread) = self.threads.pop() {
thread.join().unwrap();
}
}
}
I used the pop approach for iterating over the threads, as ownership is
required to call join on a thread. This does mean that the threads can’t be
interrupted, so dropping the thread pool may take quite a while depending on the
duration of the tasks to perform.
Performance
I was curious about the performance implications of taking a lock on receiving tasks, so I ran a number of tests comparing lots of short tasks to few long tasks that add up to the same overall expected amount of work.
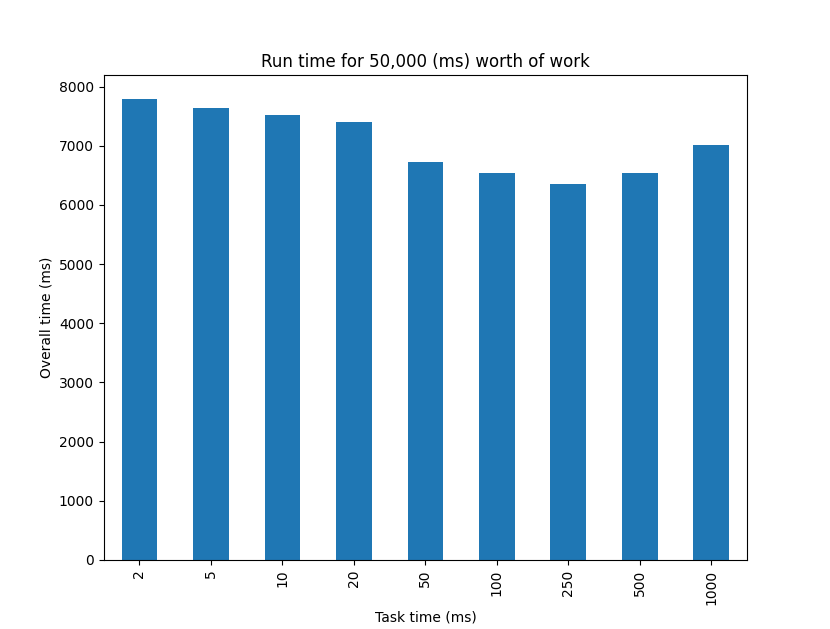
You may notice we see the best performance somewhere between 100-500ms. As we go larger than this, we start to hit tasks that run longer than the improvement possible through parallelism. For example, if we had 5 second tasks, there’s no way we could divide that up to get less than 10 seconds overall if we only have 8 cores (since we’d need to do 10 tasks’ worth of work to reach the 50,000ms mark). The more interesting aspect is that anything less than 100ms seems to have some cost associated with switching tasks. This indicates that there may be some performance benefit to a lock-free concurrency primitive that simulates a multi-producer multi-consumer channel. Although, it would be best to do a proper benchmark before pursuing an alternative.
Overall, it’s nice to see that in all cases we get at least a 6.4x improvement on compute time with this simple implementation.
I’ve linked the GitHub project below which contains some examples and has some
added tracing to reveal some of the inner-workings of the ThreadPool. One of
which is the simulation used to generate the data for the above graph. I also
split up the commits into pieces that follow the same pacing as this post. I did
not have such a smooth experience implementing this the first time. I had a
completely different approach with far more mutexes and overall bookkeeping.
Links
Footnotes
-
None of which will ever see the light of day. ↩
-
I say “only”, but it’s a really jam-packed standard library. ↩
-
In fact, the
std::thread::available_parallelism()method returns aResult<NonZeroUsize>. ↩